Architecture
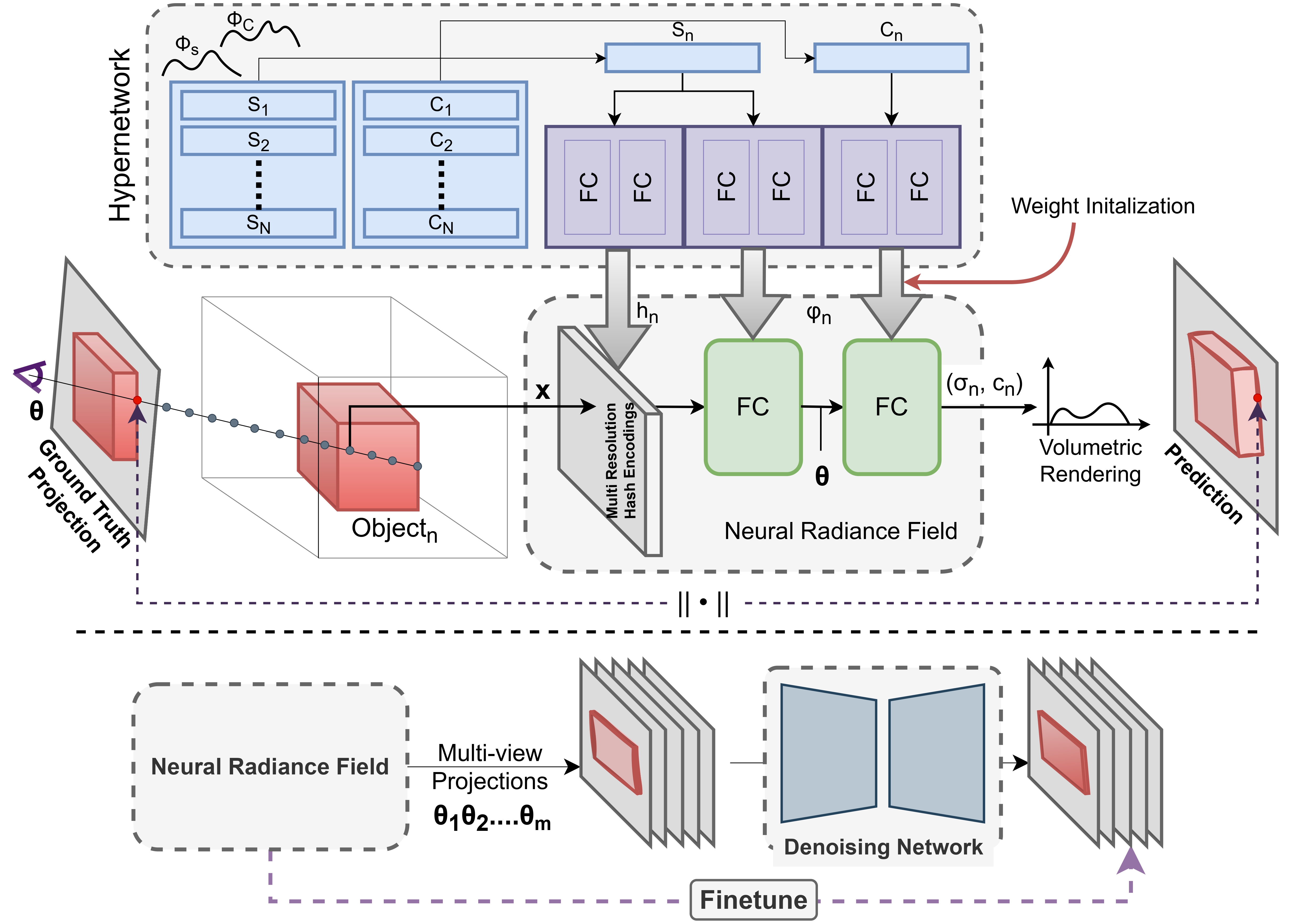
Architectural Overview: HyP-NeRF is trained and inferred in two steps. In the first step (top), our hypernetwork, M is trained to predict the parameters of a NeRF model, fncorresponding to object instance n. At this stage, the NeRF model acts as a set of differentiable layers to compute the volumetric rendering loss, using which M is trained on a set of N objects, thereby learning a prior Φ = {ΦS, ΦC} over the shape and color codes given by S and C respectively. In the second step (bottom), the quality of the predicted multiview consistent NeRF, fn is improved using a denoising network trained directly in the image space. To do this, fn is rendered from multiple known poses to a set of images that are improved to photorealistic quality. fn is then finetuned on these improved images. Importantly, since fn is only finetuned and not optimized from scratch, and thus fn retains the multiview consistency whilst improving in terms of texture and shape quality.